



技术丨小团队微服务落地实践
-
2020-06-11
Linkflow
作者:Linkflow运维开发负责人 – 徐鹏
我们的产品是Linkflow,企业运营人员使用的客户数据平台(CDP)。产品的一个重要部分类似企业版的”捷径”,让运营人员可以像搭乐高积木一样创建企业的自动化流程,无需编程即可让数据流动起来。从这一点上,我们的业务特点就是聚少成多,把一个个服务连接起来就成了数据的海洋。理念上跟微服务一致,一个个独立的小服务最终实现大功能。当然我们一开始也没有使用微服务,当业务还未成型就开始考虑架构,那么就是”过度设计”。另一方面需要考虑的因素就是”人”,有没有经历过微服务项目的人,团队是否有devops文化等等,综合考量是否需要微服务化。
要不要微服务
微服务的好处是什么?
相比于单体应用,每个服务的复杂度会下降,特别是数据层面(数据表关系)更清晰,不会一个应用上百张表,新员工上手快。
对于稳定的核心业务可以单独成为一个服务,降低该服务的发布频率,也减少测试人员压力。
可以将不同密集型的服务搭配着放到物理机上,或者单独对某个服务进行扩容,实现硬件资源的充分利用。
部署灵活,在私有化项目中,如果客户有不需要的业务,那么对应的微服务就不需要部署,节省硬件成本,就像上文提到的乐高积木理念。
微服务有什么挑战?
一旦设计不合理,交叉调用,相互依赖频繁,就会出现牵一发动全身的局面。想象单个应用内service层依赖复杂的场面就明白了。
项目多了,轮子需求也会变多,需要有人专注公共代码的开发。
开发过程的质量需要通过持续集成(CI)严格把控,提高自动化测试的比例,因为往往一个接口改动会涉及多个项目,光靠人工测试很难覆盖所有情况。
发布过程会变得复杂,因为微服务要发挥全部能力需要容器化的加持,容器编排就是最大的挑战。
线上运维,当系统出现问题需要快速定位到某个机器节点或具体服务,监控和链路日志分析都必不可少。
下面详细说说我们是怎么应对这些挑战的
开发过程的挑战
持续集成
通过CI将开发过程规范化,串联自动化测试和人工Review。
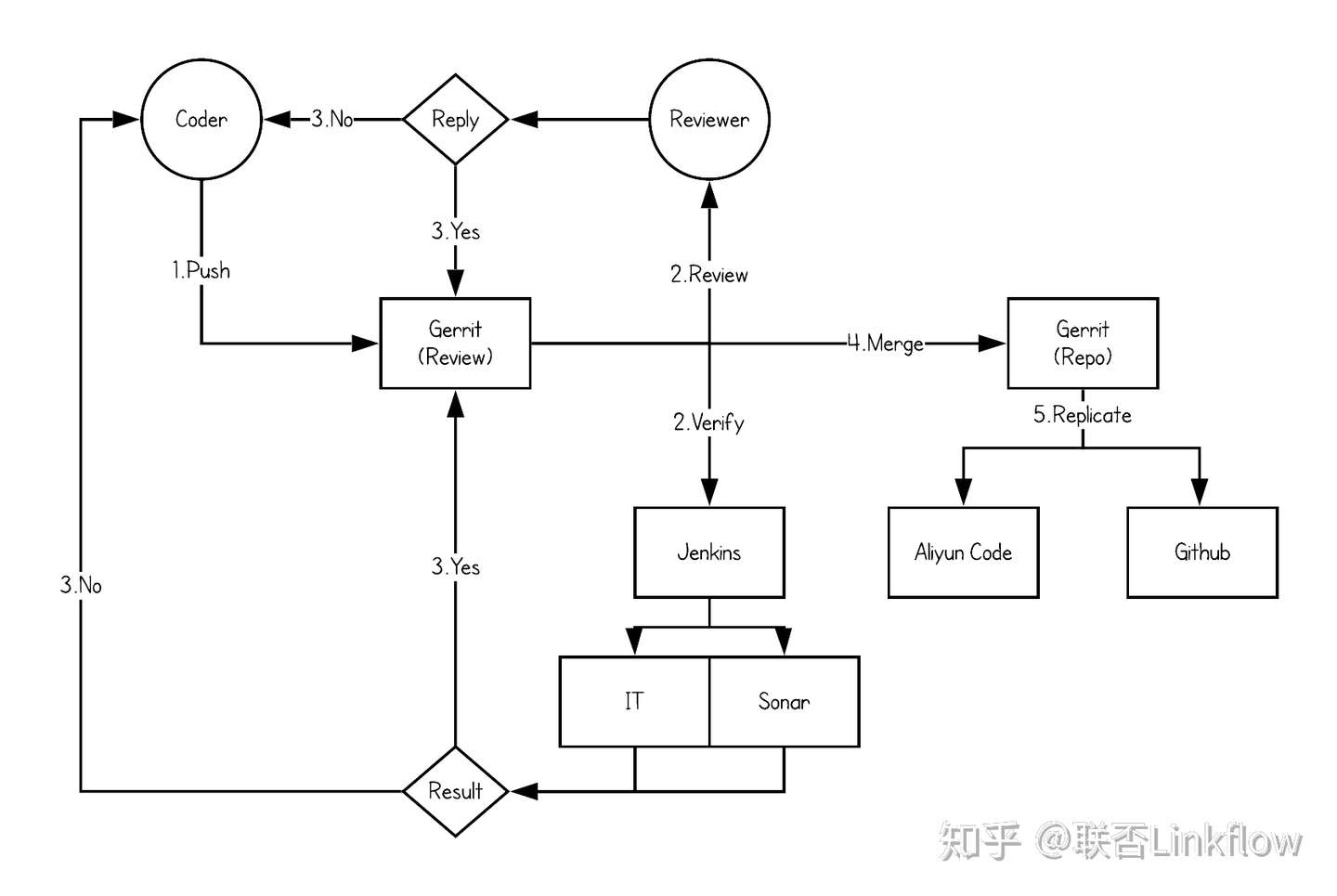
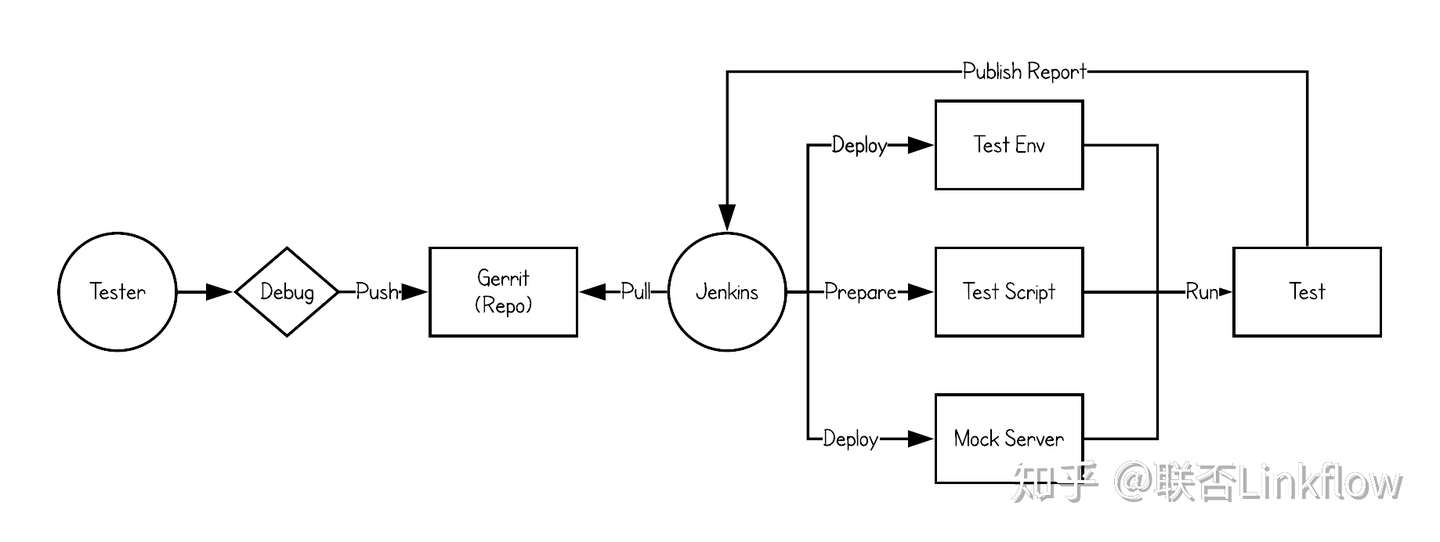
我们使用Gerrit作为代码&分支管理工具,在流程管理上遵循Gitlab的工作流模型。
开发人员提交代码至Gerrit的magic分支
代码Review人员Review代码并给出评分
对应Repo的Jenkins job监听分支上的变动,触发Build job。经过IT和Sonar的静态代码检查给出评分
Review和Verify皆通过之后,相应Repo的负责人将代码merge到真实分支上
若有一项不通过,代码修改后重复过程
Gerrit将代码实时同步备份至的两个远程仓库中
集成测试
一般来说代码自动执行的都是单元测试(Unit Test),即不依赖任何资源(数据库,消息队列)和其他服务,只测试本系统的代码逻辑。但这种测试需要mock的部分非常多,一是写起来复杂,二是代码重构起来跟着改的测试用例也非常多,显得不够敏捷。而且一旦要求开发团队要达到某个覆盖率,就会出现很多造假的情况。所以我们选择主要针对API进行测试,即针对controller层的测试。另外对于一些公共组件如分布式锁,json序列化模块也会有对应的测试代码覆盖。测试代码在运行时会采用一个随机端口拉起项目,并通过http client对本地API发起请求,测试只会对外部服务做mock,数据库的读写,消息队列的消费等都是真实操作,相当于把Jmeter的事情在Java层面完成一部分。Spring Boot项目可以很容易的启动这样一个测试环境,代码如下:
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
测试过程的http client推荐使用io.rest-assured:rest-assured支持JsonPath,十分好用。
测试时需要注意的一个点是测试数据的构造和清理。构造又分为schema的创建和测试数据的创建。
schema由flyway处理,在启用测试环境前先删除所有表,再进行表的创建。
测试数据可以通过
@Sql读取一个sql文件进行创建,在一个用例结束后再清除这些数据。
顺带说一下,基于flyway的schema upgrade功能我们封成了独立的项目,每个微服务都有自己的upgrade项目,好处一是支持command-line模式,可以细粒度的控制升级版本,二是也可以支持分库分表以后的schema操作。upgrade项目也会被制作成docker image提交到docker hub。
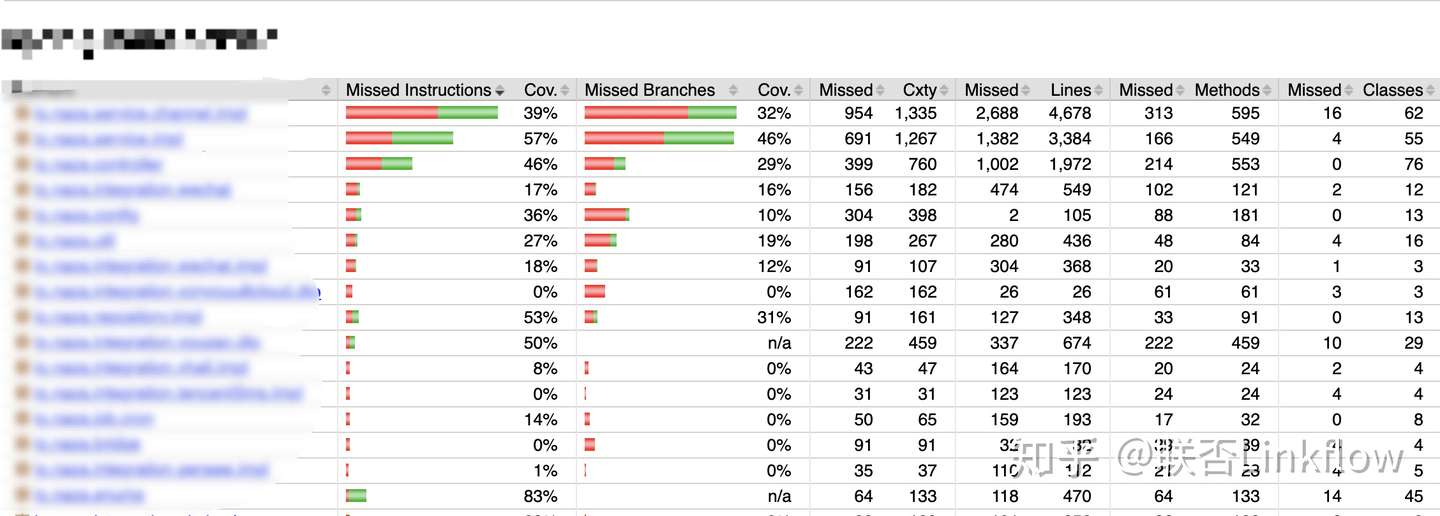
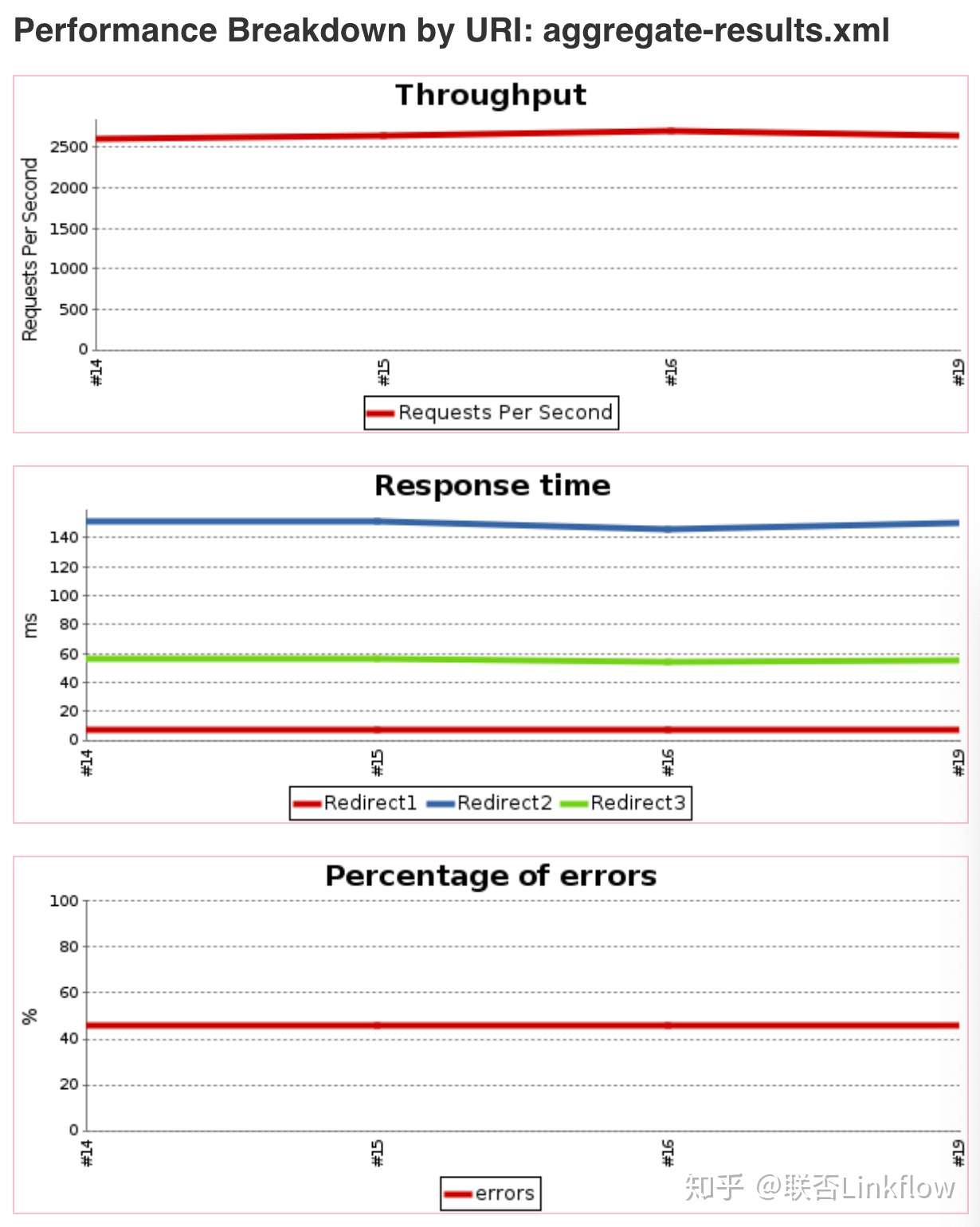
测试在每次提交代码后都会执行,Jenkins监听gerrit的提交,通过docker run -rm {upgrade项目的image}先执行一次schema upgrade,然后gradle test执行测试。最终会生成测试报告和覆盖率报告,覆盖率报告采用jacoco的gradle插件生成。如图。

这里多提一点,除了集成测试,服务之间的接口要保证兼容,实际上还需要一种consumer-driven testing tool,就是说接口消费端先写接口测试用例,然后发布到一个公共区域,接口提供方发布接口时也会执行这个公共区域的用例,一旦测试失败,表示接口出现了不兼容的情况。比较推荐大家使用Pact或是Spring Cloud Contact。我们目前的契约基于”人的信任“,毕竟服务端开发者还不多,所以没有必要使用这样一套工具。
集成测试的同时还会进行静态代码检查,我们用的是sonar,当所有检查通过后jenkins会+1分,再由reviewer进行代码review。
自动化测试
单独拿自动化测试出来说,就是因为它是质量保证的非常重要的一环,上文能在CI中执行的测试都是针对单个微服务的,那么当所有服务(包括前端页面)都在一起工作的时候是否会出现问题,就需要一个更接近线上的环境来进行测试了。
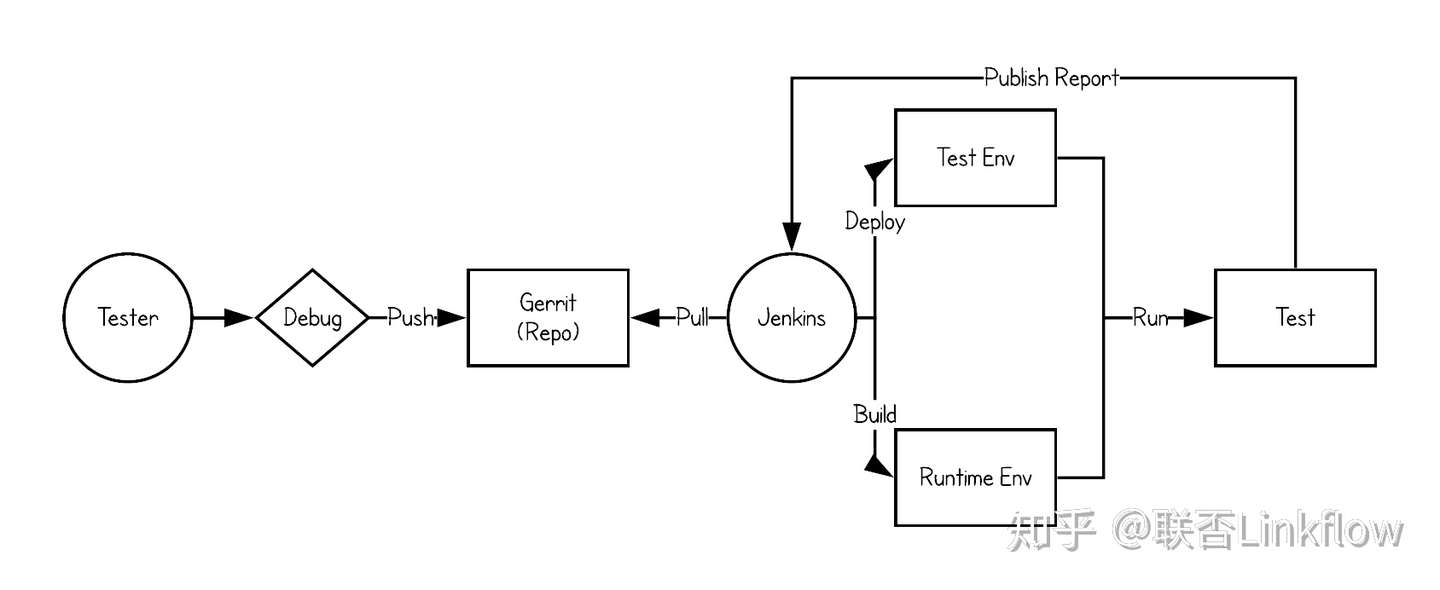
在自动化测试环节,我们结合Docker提高一定的工作效率并提高测试运行时环境的一致性以及可移植性。在准备好基础的Pyhton镜像以及Webdriver(selenium)之后,我们的自动化测试工作主要由以下主要步骤组成
测试人员在本地调试测试代码并提交至Gerrit
Jenkins进行测试运行时环境的镜像制作,主要将引用的各种组件和库打包进一个Python的基础镜像
通过Jenkins定时或手动触发,调用环境部署的job将专用的自动化测试环境更新,然后拉取自动化测试代码启动一次性的自动化测试运行时环境的Docker容器,将代码和测试报告的路径镜像至容器内
自动化测试过程将在容器内进行
测试完成之后,不必手动清理产生的各种多余内容,直接在Jenkins上查看发布出来的测试结果与趋势
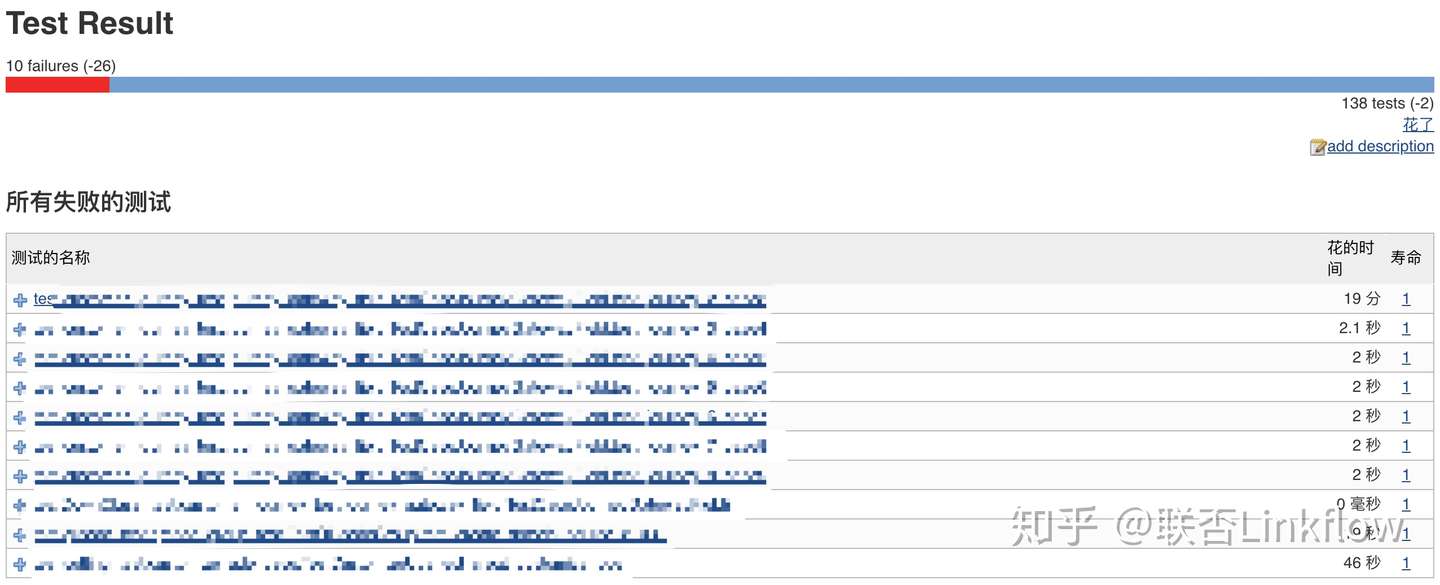
关于部分性能测试的执行,我们同样也将其集成到Jenkins中,在可以直观的通过一些结果数值来观察版本性能变化情况的回归测试和基础场景,将会很大程度的提高效率、便捷的观察趋势
测试人员在本地调试测试代码并提交至Gerrit
通过Jenkins定时或手动触发,调用环境部署的job将专用的性能测试环境更新以及可能的Mock Server更新
拉取最新的性能测试代码,通过Jenkins的性能测试插件来调用测试脚本
测试完成之后,直接在Jenkins上查看通过插件发布出来的测试结果与趋势
发布过程的挑战
上面提到微服务一定需要结合容器化才能发挥全部优势,容器化就意味线上有一套容器编排平台。我们目前采用是Redhat的Openshift。所以发布过程较原来只是启动jar包相比要复杂的多,需要结合容器编排平台的特点找到合适的方法。
镜像准备
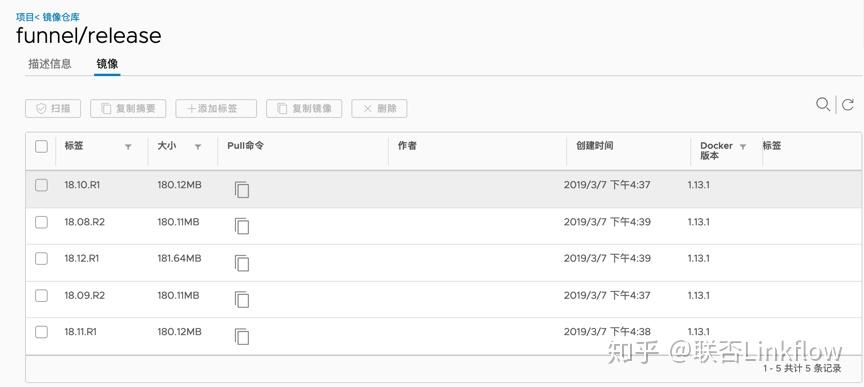
公司开发基于gitlab的工作流程,git分支为master,pre-production和prodution三个分支,同时生产版本发布都打上对应的tag。每个项目代码里面都包含dockerfile与jenkinsfile,通过jenkins的多分支pipeline来打包docker镜像并推送到harbor私库上。
docker镜像的命令方式为 项目名/分支名:git_commit_id,如 funnel/production:4ee0b052fd8bd3c4f253b5c2777657424fccfbc9,tag版本的docker镜像命名为 项目名/release:tag名,如 funnel/release:18.10.R1
在jenkins中执行build docker image job时会在每次pull代码之后调用harbor的api来判断此版本的docker image是否已经存在,如果存在就不执行后续编译打包的stage。在jenkins的发布任务中会调用打包job,避免了重复打包镜像,这样就大大的加快了发布速度。
数据库Schema升级
数据库的升级用的是flyway,打包成docker镜像后,在openshift中创建job去执行数据库升级。job可以用最简单的命令行的方式去创建
oc run upgrade-foo --image=upgrade/production --replicas=1 --restart=OnFailure --command -- java -jar -Dprofile=production /app/upgrade-foo.jar
脚本升级任务也集成在jenkins中。
容器发布
openshift有个特别概念叫DeploymentConfig,原生k8s Deployment与之相似,但openshift的DeploymentConfig功能更多些。
Deploymentconfig关联了一个叫做ImageStreamTag的东西,而这个ImagesStreamTag和实际的镜像地址做关联,当ImageStreamTag关联的镜像地址发生了变更,就会触发相应的DeploymentConfig重新部署。我们发布是使用了jenkins+openshift插件,只需要将项目对应的ImageStreamTag指向到新生成的镜像上,就触发了部署。
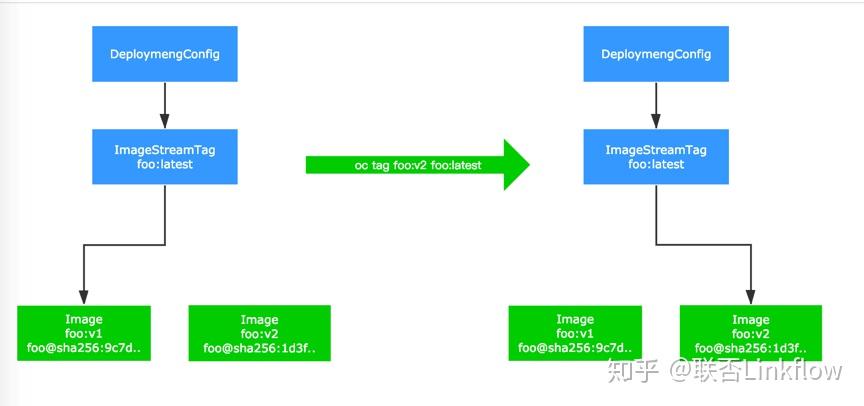
如果是服务升级,已经有容器在运行怎么实现平滑替换而不影响业务呢?
配置Pod的健康检查,Health Check只配置了ReadinessProbe,没有用LivenessProbe。因为LivenessProbe在健康检查失败之后,会将故障的pod直接干掉,故障现场没有保留,不利于问题的排查定位。而ReadinessProbe只会将故障的pod从service中踢除,不接受流量。使用了ReadinessProbe后,可以实现滚动升级不中断业务,只有当pod健康检查成功之后,关联的service才会转发流量请求给新升级的pod,并销毁旧的pod。
readinessProbe:
failureThreshold: 4
httpGet:
path: /actuator/metrics
port: 8090
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 15
successThreshold: 2
timeoutSeconds: 2
线上运维的挑战
服务间调用
Spring Cloud使用eruka接受服务注册请求,并在内存中维护服务列表。当一个服务作为客户端发起跨服务调用时,会先获取服务提供者列表,再通过某种负载均衡算法取得具体的服务提供者地址(ip + port),即所谓的客户端服务发现。在本地开发环境中我们使用这种方式。
由于Openshift天然就提供服务端服务发现,即service模块,客户端无需关注服务发现具体细节,只需知道服务的域名就可以发起调用。由于我们有nodejs应用,在实现eureka的注册和去注册的过程中都遇到过一些问题,不能达到生产级别。所以决定直接使用service方式替换掉eureka,也为以后采用service mesh做好铺垫。具体的做法是,配置环境变量EUREKA_CLIENT_ENABLED=false,RIBBON_EUREKA_ENABLED=false,并将服务列表如 FOO_RIBBON_LISTOFSERVERS: '[http://foo:8080](http://foo:8080/)' 写进configmap中,以envFrom: configMapRef方式获取环境变量列表。
如果一个服务需要暴露到外部怎么办,比如暴露前端的html文件或者服务端的gateway。
Openshift内置的haproxy router,相当于k8s的ingress,直接在Openshift的web界面里面就可以很方便的配置。我们将前端的资源也作为一个Pod并有对应的Service,当请求进入haproxy符合规则就会转发到ui所在的Service。router支持A/B test等功能,唯一的遗憾是还不支持url rewrite。
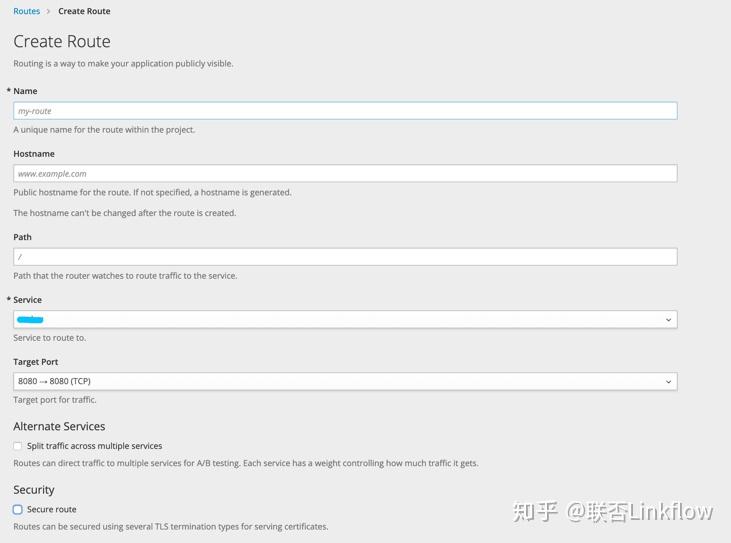
对于需要url rewrite的场景怎么办?那么就直接将nginx也作为一个服务,再做一层转发。流程变成 router → nginx pod → 具体提供服务的pod。
链路跟踪
开源的全链路跟踪很多,比如spring cloud sleuth + zipkin,国内有美团的CAT等等。其目的就是当一个请求经过多个服务时,可以通过一个固定值获取整条请求链路的行为日志,基于此可以再进行耗时分析等,衍生出一些性能诊断的功能。不过对于我们而言,首要目的就是trouble shooting,出了问题需要快速定位异常出现在什么服务,整个请求的链路是怎样的。
为了让解决方案轻量,我们在日志中打印RequestId以及TraceId来标记链路。RequestId在gateway生成表示唯一一次请求,TraceId相当于二级路径,一开始与RequestId一样,但进入线程池或者消息队列后,TraceId会增加标记来标识唯一条路径。举个例子,当一次请求会向MQ发送一个消息,那么这个消息可能会被多个消费者消费,此时每个消费线程都会自己生成一个TraceId来标记消费链路。加入TraceId的目的就是为了避免只用RequestId过滤出太多日志。
实现上,通过ThreadLocal存放APIRequestContext串联单服务内的所有调用,当跨服务调用时,将APIRequestContext信息转化为Http Header,被调用方获取到Http Header后再次构建APIRequestContext放入ThreadLocal,重复循环保证RequestId和TraceId不丢失即可。如果进入MQ,那么APIRequestContext信息转化为Message Header即可(基于Rabbitmq实现)。
当日志汇总到日志系统后,如果出现问题,只需要捕获发生异常的RequestId或是TraceId即可进行问题定位。
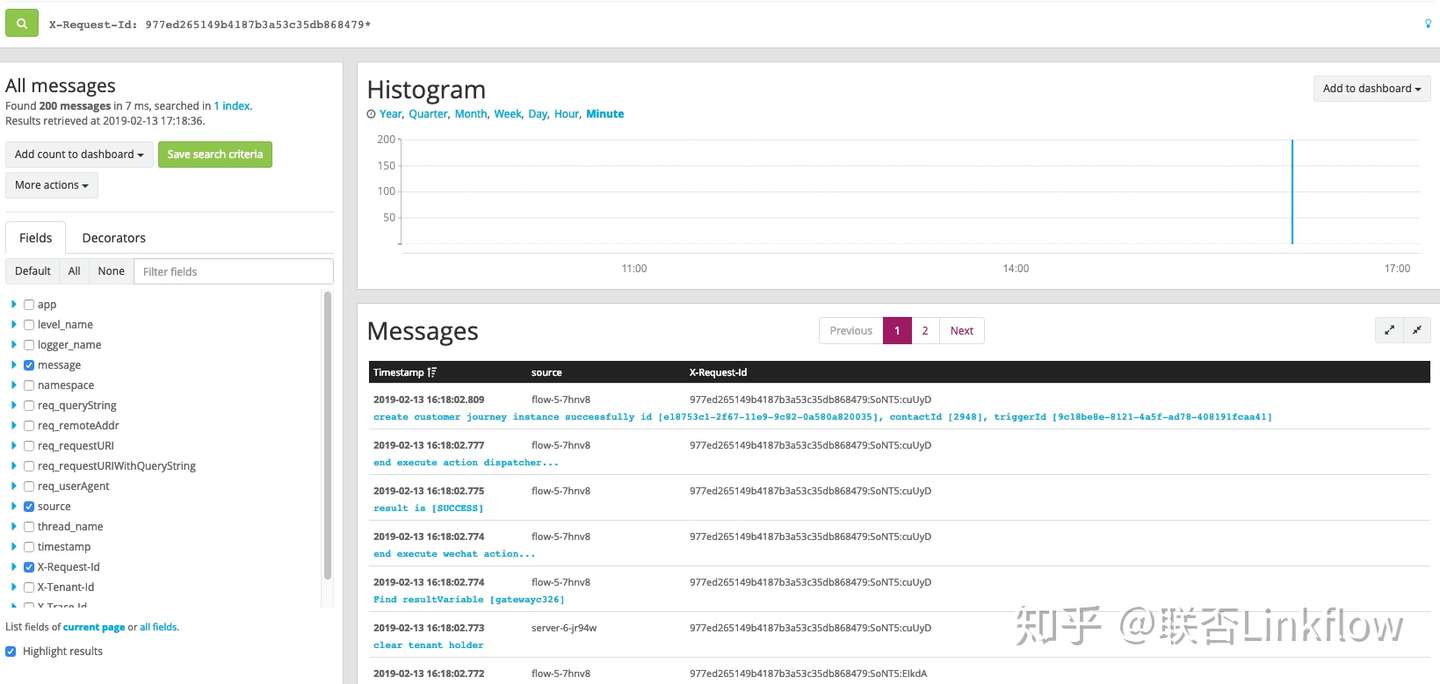
经过一年来的使用,基本可以满足绝大多数trouble shooting的场景,一般半小时内即可定位到具体业务。
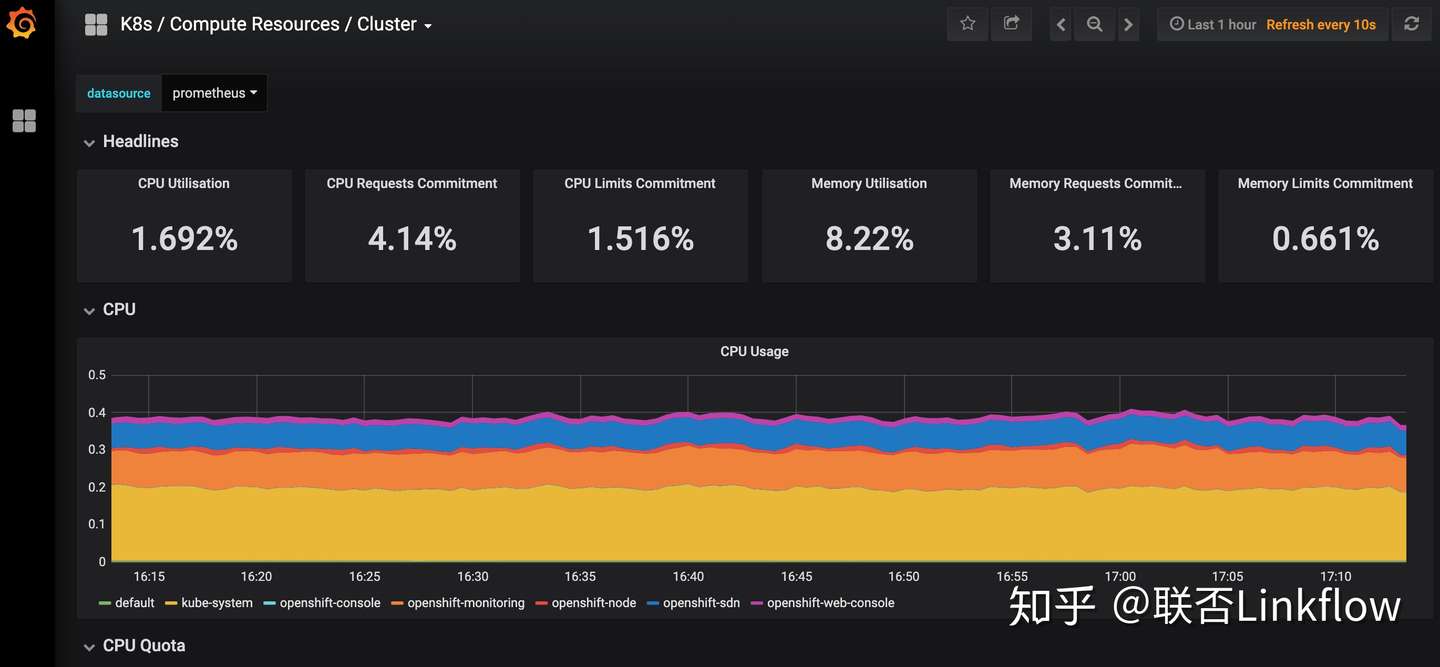
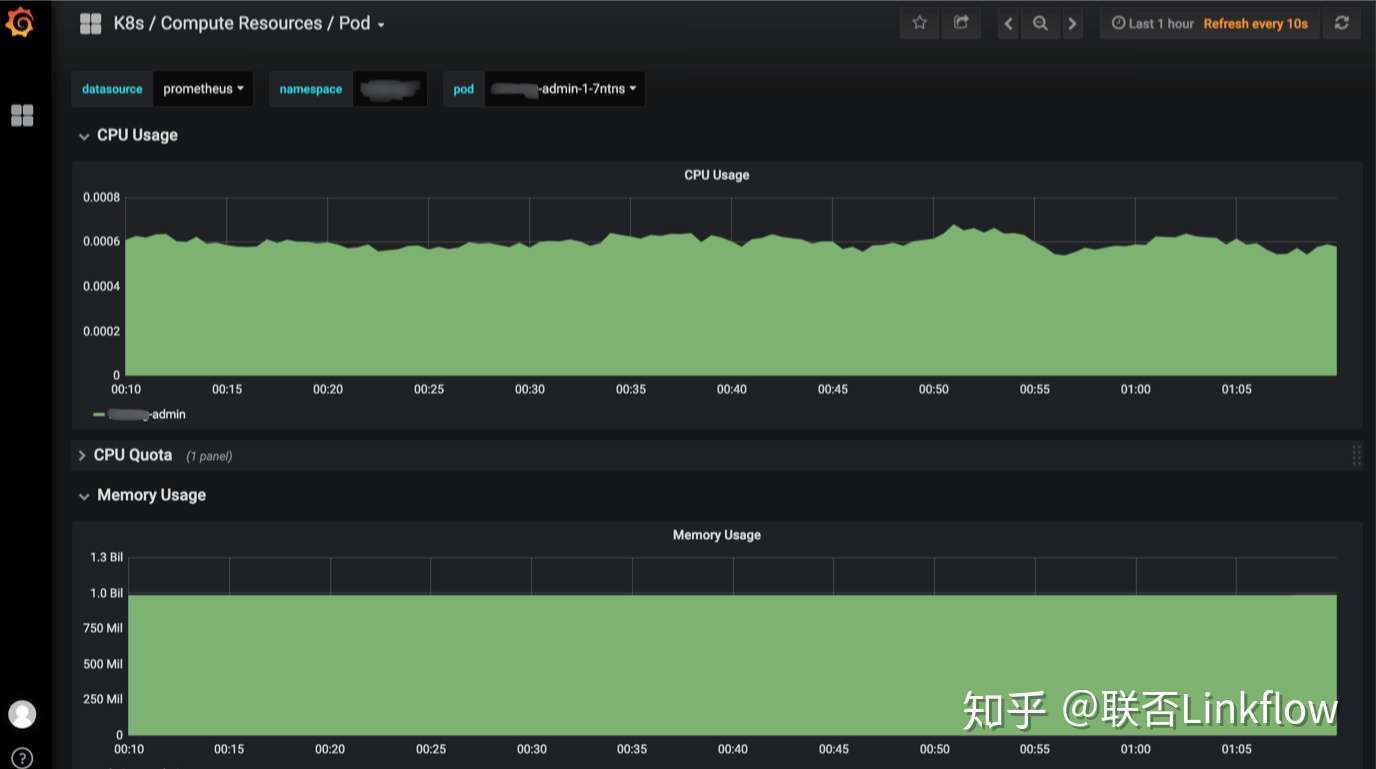
容器监控
容器化前监控用的是telegraf探针,容器化后用的是prometheus,直接安装了openshift自带的cluster-monitoring-operator。自带的监控项目已经比较全面,包括node,pod资源的监控,在新增node后也会自动添加进来。
Java项目也添加了prometheus的监控端点,只是可惜cluster-monitoring-operator提供的配置是只读的,后期将研究怎么将java的jvm监控这些整合进来。
MORE
开源软件是对中小团队的一种福音,无论是Spring Cloud还是k8s都大大降低了团队在基础设施建设上的时间成本。当然其中有更多的话题,比如服务升降级,限流熔断,分布式任务调度,灰度发布,功能开关等等都需要更多时间来探讨。对于小团队,要根据自身情况选择微服务的技术方案,不可一味追新,适合自己的才是最好的。
Q&A
Q:服务治理问题,服务多了,调用方请求服务方,超时或者网络抖动等需要可能需要重试,客户端等不及了怎么办?比如A->B->C,等待超时时间都是6s,因为C服务不稳定,B做了重试,那么增加了A访问B的时长,导致连锁反应?
A:服务发现有两种,一种是客户端发现,一种是服务端发现。如果是客户端发现的话,客户端需要设置超时时间,如果超时客户端需要自己重试,此时如果是轮询应该可以调用到正常的服务提供方。Spring Coud的Ribbon就是对这一流程做了封装。至于连锁反应的问题,需要有降级熔断,配置Hystrix相关参数并实现fallback方法。看源码能够发现hystrixTimeout要大于ribbonTimeout,即Hystrix熔断了以后就不会重试了,防止雪崩。
Q:JVM如何export,是多container吗,监控数据,搜刮到Prometheus?
A:JVM的用的是Prometheus埋点,Java里面的路径是/actuator/prometheus,在yaml里面定义http://prometheus.io/path: /actuator/prometheu http://prometheus.io/port: '8090' http://prometheus.io/scrape: 'true',再在Prometheus里面进行相应的配置,就可以去搜刮到这些暴露的指标。
Q:Kubernetes和OpenShift哪个更适合微服务的使用?
A:OpenShift是Kubernetes的下游产品,是Kubernetes企业级的封装,都是一样的。OpenShift封装有功能更强大的监控管理工具,并且拥有Kubernetes不太好做的权限管理系统。
Q:可以介绍一下你们在优化镜像体积上面做了哪些工作吗?
A:RUN命令写在一行上,产生的临时文件再删掉。只安装必须要的包。JDK和Node.Js都有slim镜像,一般都是以那个为基础镜像去做。
Q:数据库是否真的适合最容器化?
A:我们生产数据库用的是RDS,开发测试环境用的是Docker Compose起的。从理论上,数据库最好做容器化,模块的独立性高,需要考虑好的是数据库容器的数据永久化存储。
Q:为什么选择了OpenShift?
A:因为OpenShift有个很方便的UI,大多数都可以在UI里面操作,包括yaml文件的修改,重新部署回退等操作。对于开发测试来讲,学习的成本比较低,不需要花时间熟悉CLI操作。
Q:Python基础镜像怎么制作最好,如果加入GCC,C++等编译需要的工具,镜像会特别大?
A:Python基础镜像直接从Python官方Docker镜像上做就行了。GCC,C++那个做出来的镜像大也没办法。如果没这个需求的话,可以用Python slim镜像去做。
Q:在Gateway中Ribbon如何根据客户端的IP负载到对应的IP注册的服务?
A:如果使用了Eureka的话,服务提供方启动时会自注册到Eureka。服务调用方发起请求前会从Eureka上读取提供方的列表,再进行负载均衡定位到具体的IP和Port。如果跟我们一样直接使用Kubernetes的Service,其实就是由Kubernetes控制了,服务调用方访问Kubernetes暴露的Service,然后由Kubernetes负载均衡到这个Service背后的具体的Pod。
Q:如何实现远程发布、打包?
A:Jenkins打包镜像发布到Harbor上,Jenkins再调用OpenShift去从Harbor上拉取镜像,重新tag一下就可以实现发布。
Q:譬如客户端IP是10,希望Gateway负载到10注册的order服务,而不是其他IP注册的order服务,希望开发使用集中的Eureka和Gateway?
A:是说不需要负载均衡?最简单的可以看下Ribbon的实现,负载均衡算法可以自己定义,如果只是要固定IP的话,那么遍历服务列表再判断就可以了。两次判断,if serviceId=order,if ip = 10。
Q:Docker管理工具一般用什么?
A:Kubernetes,简称k8s,是目前较热门的Docker管理工具。离线安装Kubernetes比较繁琐,有两款比较好的自动化部署工具,Ubuntu系统的Juju和Red Hat系统的OpenShift,OpenShift又称为企业版的Kubernetes,有收费的企业版和免费版。
Q:Prometheus是每个集群部署一套吗?存储是怎么处理?存本地还是?
A:每个集群部署一套,存储暂时存在本地,没有用持久化存储。因为现在环境都是在云上面,本身云厂商就有各种的监控数据,所以Prometheus的监控数据也只是做个辅助作用。
-
本文作者:Linkflow
责任编辑:马亚蒙
本文来源:牛透社
-
分享到:


























